近日,我校计算机科学与工程学院周雨熙副教授团队的博士研究生龙泳潮在国际人工智能顶会ICLR 2026上发表题为《Copy-Paste to Mitigate Large Language Model Hallucinations》的文章。国际学习表征会议(International Conference on Learning Representations, ICLR)与NeurIPS、ICML并称为人工智能领域三大顶级会议,是CCF-A类推荐会议,在全球享有极高的学术声誉。
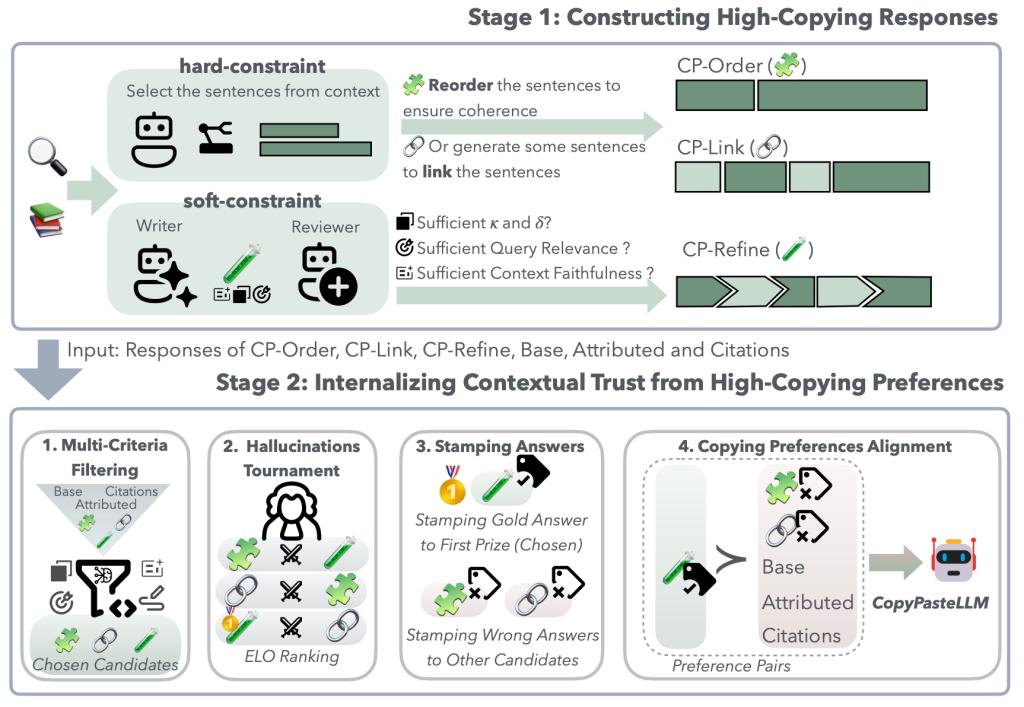
针对现有大模型因“幻觉”导致的信任危机,目前业界常用对齐微调或检索增强生成(RAG)等优化方法,然而其仍然面临模型自由发挥或二次重写带来失控的风险,大多只能在概率上“减少”幻觉,却始终无法做到“彻底消除”。为了打破这一瓶颈,颠覆现有大模型基于概率逼近的生成逻辑,本文创新性地提出Copy-Paste极端生成新范式——CopyPasteLLM生成机制。论文首先探索并设计了三种渐进式提示策略:CP-Order(硬约束,零自由发挥)、CP-Link(桥接,允许模型生成过渡短语)、CP-Refine(软约束,引入 Writer-Reviewer “博弈”迭代机制),无需任何人工标注,自动构建“极端忠实”的偏好数据,并进一步将生成的偏好数据进行直接偏好优化(DPO)训练得到CopyPasteLLM,让“遵循上下文”这一行为从表面策略升华为底层信念。该范式引导模型在保持语义创造性的同时,严格恪守事实边界,从根本上抑制对内部参数化知识的过度依赖,从而实现对给定上下文忠实遵循的“零幻觉”终极目标。
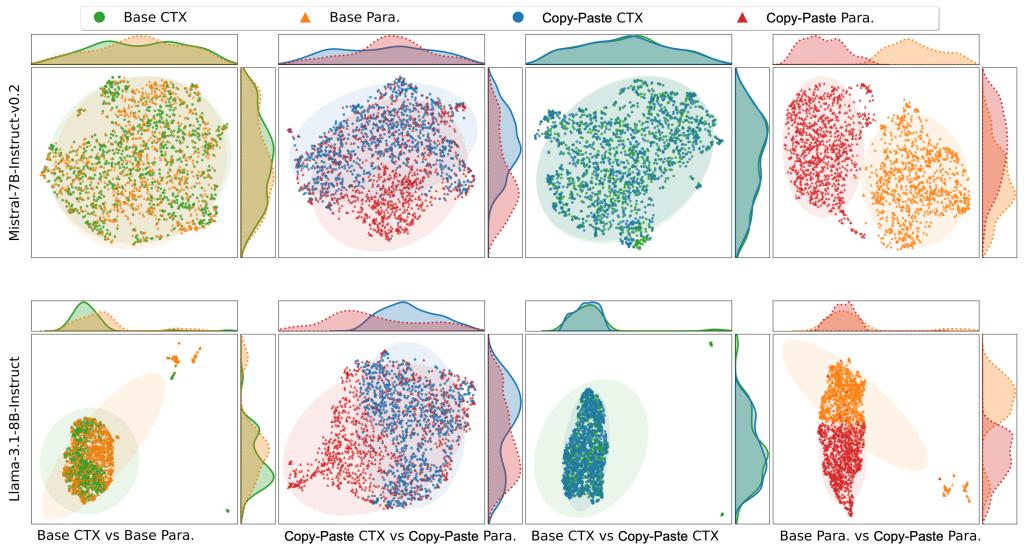
实验表明,该方法在多个严苛基准上均取得最优性能,相比最强基线准确率提升高达24.5%,而训练数据仅需365条,为同类工作的五十分之一,展现了极高的数据效率和泛化能力。此外,论文揭示了CopyPasteLLM的核心机制——大模型内部发生了什么?CopyPasteLLM并非简单增强对外部上下文的复制,而是重新校准了对内部参数知识的依赖,即,并没有“强化”对外部上下文的关注,而是“抑制”了对内部参数化知识的过度自信,从而更加信任并严格遵循所提供的上下文信息。




