AAAI人工智能会议(AAAI Conference on Artificial Intelligence)是人工智能领域的重要国际会议,是CCF-A类推荐会议。AAAI2026将于2026年1月20日-27日在新加坡举办。今年共有23680篇论文投稿,最终4167篇论文接收,录用率17.6%。计算机学院共有4篇论文被AAAI2026录用,涉及主流文本生成图像、图象篡改检测、时序分类研究。录用论文简要介绍如下:
论文1
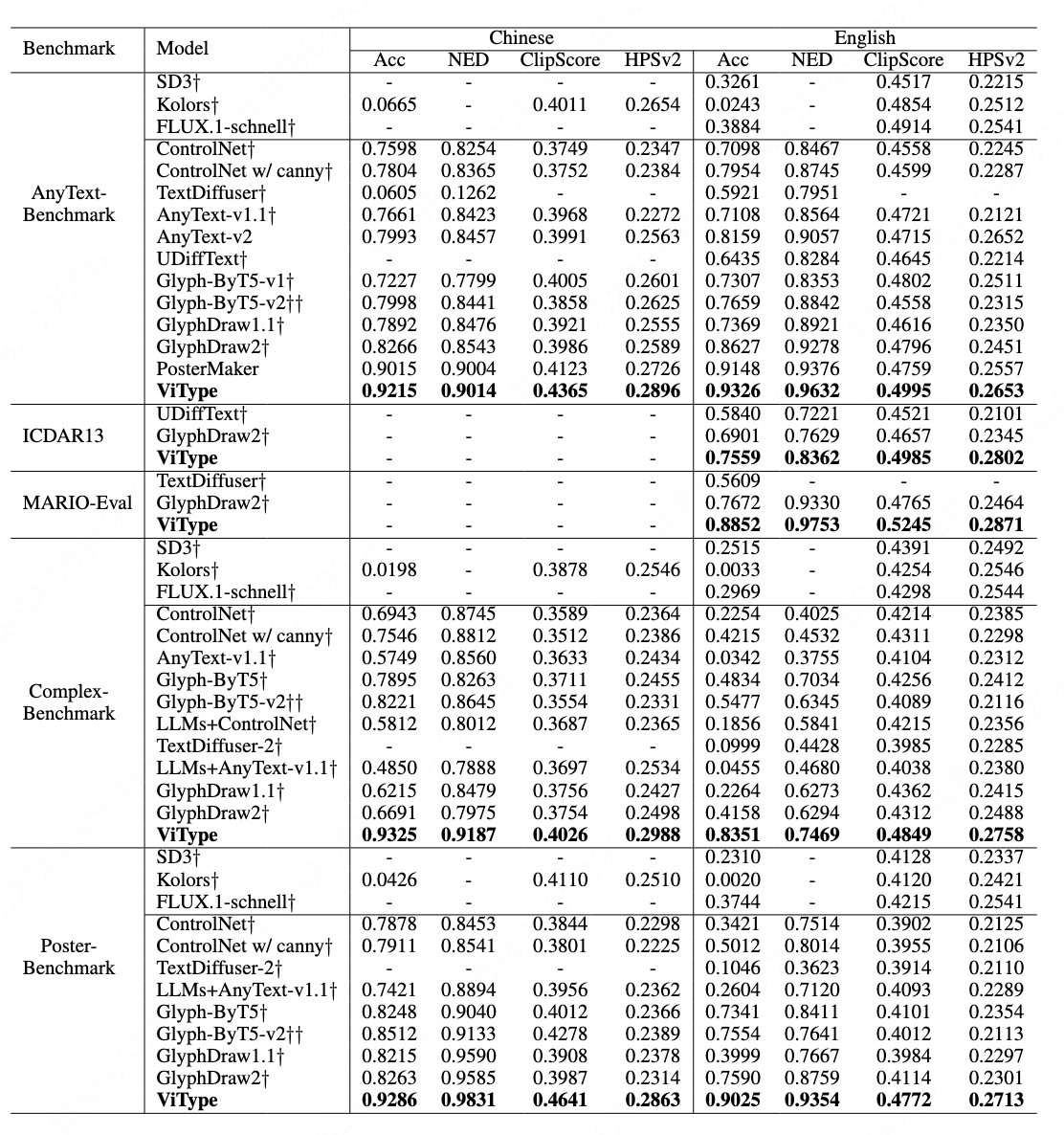
论文题目:ViType: High-Fidelity Visual Text Rendering via Glyph-Aware Multimodal Diffusion
论文概述:当前主流文本生成图像(T2I)模型在视觉文本渲染方面仍面临三大难题:1)缺乏字形级理解:CLIP、T5等文本编码器无法感知字符形状与结构;2)语义与字形混淆:模型常将“要渲染的文本”与“语义描述”混为一谈;3)图像缺乏美感:文字与背景在颜色、光影、透视上无法无缝融合。
为了解决以上问题,论文提出了一种字形感知的多模态扩散框架ViType,并首次在扩散模型中引入VQA式字形-文本对齐机制,用“认字+写字+审美”三段式训练,让扩散模型首次在图像中高保真、多语言、风格化 地渲染任意文字,全面刷新5大基准榜单SOTA。其主要创新点包括:1)文本-字形对齐:引入VQA机制,将字符图像与其属性描述在嵌入空间中对齐,增强模型对字形的视觉理解力。2)多模态联合渲染:通过MMDiT架构同步融合字形视觉嵌入与语义文本token,确保跨模态特征一致性,从而生成结构准确、风格统一的文本图像。3)美学增强训练:构建超2000万高质量图文对的多源数据集,专注于文本属性与背景融合,提升整体视觉美感与排版质量。
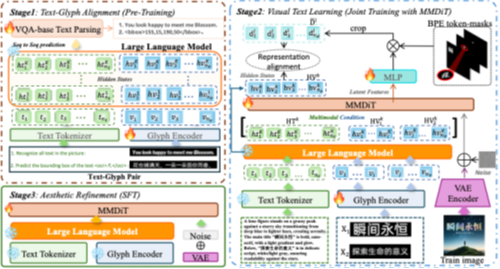

该论文第一作者是天津理工大学计算机学院博士研究生高立帅,导师是高赞教授,并由Jun-Yan He, Yingsen Zeng, Jie Hu, Xiaopeng Sun, Yujie Zhong,Xiaoming Wei等共同指导完成。该论文被录取为Oral口头报告。
论文2
论文题目:Amplifying Discrepancies: Exploiting Macro and Micro Inconsistencies for Image Manipulation Localization
论文概述:针对日益精细的伪造手法,近年的研究尝试从噪声模式、频域特征、多尺度边缘等多视角出发,或结合对比学习与先验知识,设计出一系列高性能检测模型。然而,目前的方法没有充分挖掘“被篡改区域”和“真实区域”在多层次上的内在差异,因此,论文提出了聚焦差异网络FRD-Net(Focus Region Discrepancy Network)。
该网络强调在任务驱动下显式挖掘并放大“被篡改区域—真实区域”之间的内在不一致性,通过宏观与微观两级协同建模,将篡改检测从找异常特征转变为比对真伪差异,从而实现对多类型篡改场景的精准定位与强鲁棒泛化。为落实这一思想,FRD-Net设计了简洁高效的焦点区域差异块(FRD Block),由两个关键模块构成:其一是迭代聚类模块(ICM),通过对特征进行动态聚类,自适应形成代表“可疑区域”和“真实背景”的两类聚类中心,并在反向更新中不断强化两者间的语义拉距,使模型在高维特征空间中自动突出目标级的宏观差异;其二是差分渐进模块(DPM),在局部邻域内引入角度差分与中心差分卷积,对纹理断裂、边缘不连续等细粒度痕迹进行渐进式放大,精细刻画微观结构的不一致。宏观ICM为微观DPM提供全局语义先验,微观DPM反向约束区域分割边界,两者形成高效协同的差异放大机制。在多个公开图像篡改定位基准上的系统实验表明,FRD-Net在准确率、边界质量及鲁棒性方面均显著优于现有主流方法,同时保持网络结构轻量、计算成本友好,展现出良好的工程部署潜力。该工作为图像篡改定位提供了一种面向“差异建模”的新范式,也为多媒体取证领域理解和利用真伪区域内在不一致性提供了新的研究视角与方法启示。
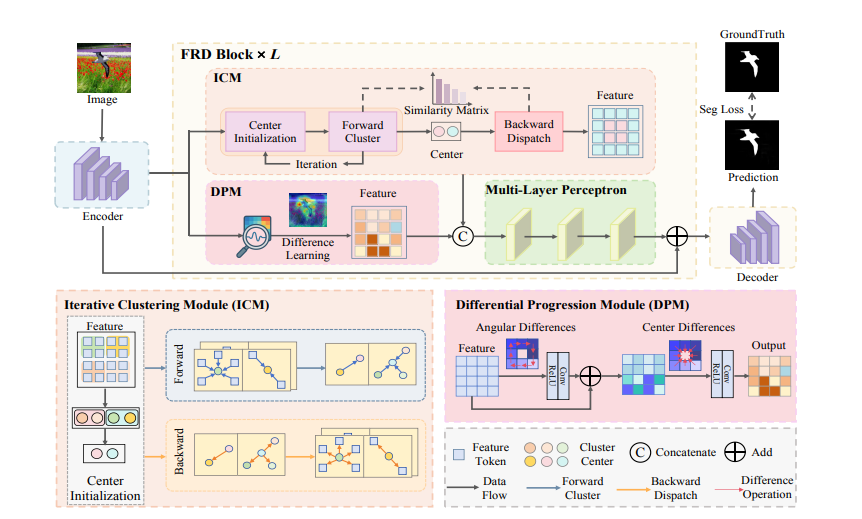
该论文第一作者是天津理工大学计算机学院博士研究生陈圣灏,导师是高赞教授,并由Yibo Zhao, Tianyi Wang, Chunjie Ma, Weili Guan, Ming Li等共同指导完成。该论文被录取为Poster墙报。
论文3:
论文题目:Duplex Rewards Optimization for Test-Time Composed Image Retrieval
论文概述:组合图像检索(Composed Image Retrieval, CIR)通过将参考图像与修改文本相结合,以检索目标图像。近年来,零样本(Zero-Shot)CIR因无需人工标记的三元组数据而备受关注。然而,这种范式不可避免地需要额外的训练语料库、存储和计算资源,限制了其实际应用。受测试时自适应(Test-Time Adaptation, TTA)进展的启发,本研究提出了测试时CIR(TT-CIR)范式,旨在在减少计算资源消耗的同时,使模型有效适应并精准检索测试样本。本研究发现,当前主流的基于奖励机制的TTA技术面临两个关键挑战:一是修改受限的奖励池,阻碍了模型对语义相关候选奖励的探索;二是保守的知识反馈,抑制了奖励信号对当前数据分布的适应性。针对上述挑战,本研究提出了一种基于双工奖励优化的测试时强化学习框架,结合反事实引导的多项式采样(Counterfactual-guided Multinomial Sampling, CMS)策略和双工奖励建模(Duplex Rewards Modeling, DRM)模块。CMS通过探索与查询视觉语义相关的候选奖励池,精准发掘有效奖励信号;DRM则生成稳定且适应性强的双工奖励,指导模型适应当前测试数据。在主流CIR基准测试中,该方法在检索准确率和效率上均优于现有方案,进一步推动了CIR模型在实际场景中的应用。
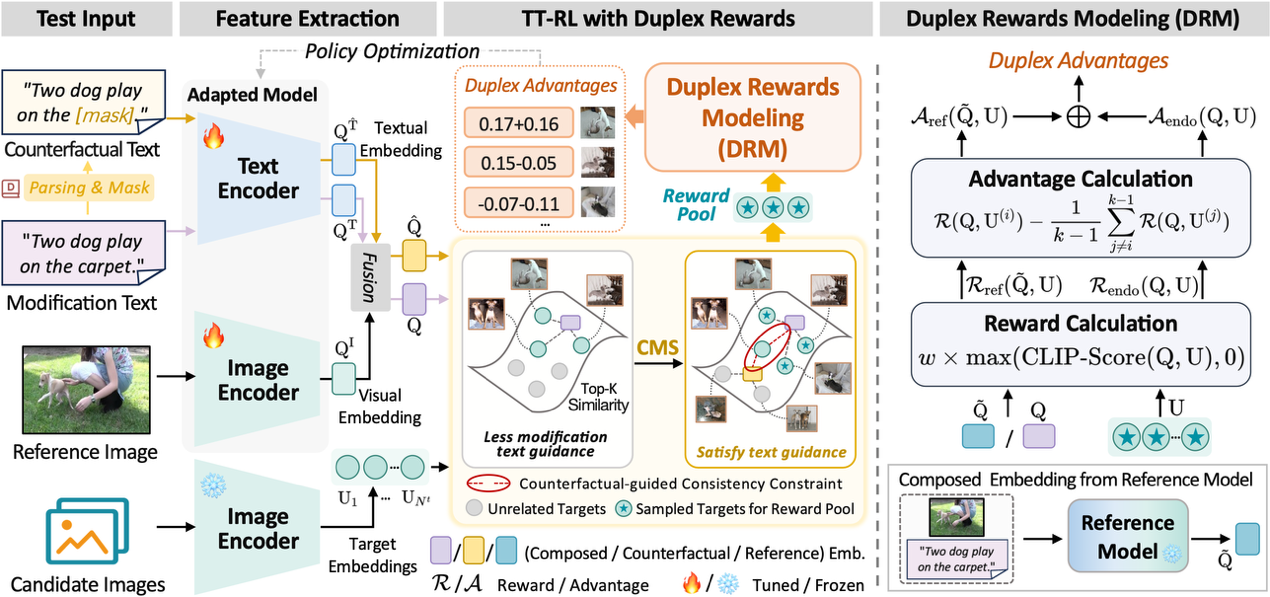
该论文第一作者是天津理工大学计算机学院博士研究生周浩樑,导师是张飞飞教授,并由Changsheng Xu共同指导完成。
论文4:
论文题目:Beyond Missing Data Imputation: Information-Theoretic Coupling of Missingness and Class Imbalance for Optimal Irregular Time Series Classification
论文概述:面对真实世界中普遍存在的不规则时间序列(IRTS)及其结构化缺失问题,现有研究多依赖插值/插补、掩码机制、或时频域建模等策略来缓解表征退化。然而,这些方法普遍将缺失视为独立噪声,忽略了信息论视角的“缺失-不平衡耦合”—即缺失模式(M)与类别标签(Y)之间存在显著的互信息。尤其在高度失衡的场景中,少数类往往呈现更高的缺失密度和更严重的频谱失真,导致判别特征被系统性削弱。基于这一理论观察,论文提出SPECTRA框架,从信息论耦合机制的角度重新界定IRTS分类问题,旨在构建具有信息论最优性保障的鲁棒表征。
SPECTRA在任务驱动的统一框架下,设计了缺失感知频率滤波(MAFF)模块、缺失模式编码器(MPE)模块和类别引导特征精炼(CGFR)模块三者协同的建模策略。具体来说,MAFF模块通过自校准谱增强(SCSE)机制,精确应对缺失引发的不可恢复的频谱失真,恢复稳定的时序依赖。MPE模块显式编码缺失模式的动态演化,将其作为判别性先验信息源纳入高维表征空间,以防止少数类表示崩溃。CGFR模块遵循信息几何原则,通过原型约束机制,强化类内紧凑性和类间可分离性,确保模型在严重失衡下保持稳定的判别性。系统实验表明,SPECTRA在多个不规则时间序列基准上显著优于现有主流模型,并在高缺失率、强失衡及传感器失效等极端条件下保持稳健性能,展示出以“结构化缺失建模”驱动的时间序列分类新范式。
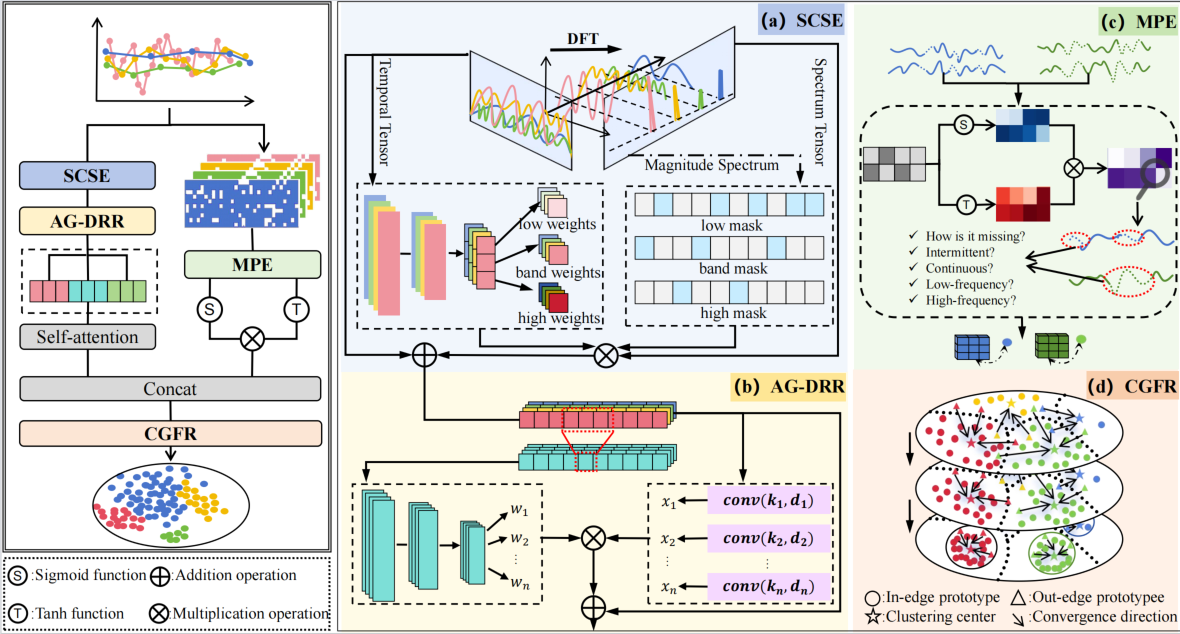
该论文第一作者是天津理工大学计算机学院博士研究生秦鑫,导师是程徐教授,并由Mengna Liu, Wenjie Wang, Tianjiao Li, Xiufeng Liu等共同指导完成。该论文被录取为Oral口头报告。




